<Spring Batch> 4. Chunk 기반 배치, ItemReader
by BFine
출처 : http://www.yes24.com/Product/Goods/99422216
스프링 배치 완벽 가이드 2/e - YES24
스프링 배치의 `Hello, World!`부터 최근 플랫폼의 발전에 따른 클라우드 네이티브 기술을 활용한 배치까지 폭넓은 스프링 배치 활용 방법과 이와 관련된 유용한 내용을 다룬다. 또한 스프링 프레임
www.yes24.com
가. Chunk 기반 배치
a. 무엇인가?
- Tasklet 기반과 다르게 하나에 처리하는 것이 아닌 기준을 두어 분할해서 처리하는 방법이다.
- ckunk를 바탕으로 Read, Process(비필수), Writer 순서로 배치처리를 진행한다.
b. 확인해보기
- 머리속으로만 생각하다보면 잘못 알고 있는 부분이 생길수 있으니 간단한 테스트를 해보자
private static int reader = 0;
private static int process = 0;
private static int writer = 0;
@Bean
public Step step(){
return stepBuilderFactory.get("Chunk")
.<Input,Output>chunk(3)
.reader(new ItemReader<Input>() {
@Override
public Input read() throws Exception, ~
Thread.sleep(1000*1);
System.out.println("### Reader "+(++reader)+"번");
return new Input();
}
}).processor(new ItemProcessor<Input, Output>() {
@Override
public Output process(Input item) throws Exception {
Thread.sleep(1000*1);
System.out.println("### Processor "+(++process)+"번");
return new Output();
}
}).writer(new ItemWriter<Output>() {
@Override
public void write(List<? extends Output> items) throws Exception {
Thread.sleep(1000*1);
System.out.println("### Writer "+(++writer)+"번");
}
})
.build();
}- chunk의 경우 제네릭으로 Input으로 사용할 객체, Output으로 사용할 객체로 나눌수 있도록 되어있다.
=> 위의 Input, Output 껍데기(?) 클래스로 만든 부분이다..
- 각각 Input은 ItemReader 와 ItemProcesser, Output은 List 형태로 ItemWriter에 사용된다.

- 코드를 보면 chunkSize에 괄호로 commit interval 이라고 되어있다. 즉 요부분이 분할하는 기준이 된다.
=> 오해할 수 있는 부분은 각각 chunkSize 만큼 실행되는거 아닌가? 라고 생각이 들수도 있다.
- 위의 코드를 실행해보면 ItemReader, ItemProcessor의 메서드는 chunkSize 수 만큼 실행되는 반면에
ItemWriter의 메서드는 한번만 실행된 것을 볼 수 있다. 즉 chunkSize만큼의 Item을 한번에 처리한다.
=> 자세한 부분은 아래에 테스트 한 부분이 있다.

나. ItemReader
a. 무엇인가?
- 위의 실행에서 알수 있듯이 입력데이터를 읽는 부분을 담당하는 인터페이스이다.
- 생각보다 더 다양한 입력데이터를 읽을수 있는 구현체들이 존재한다.
b. 특징
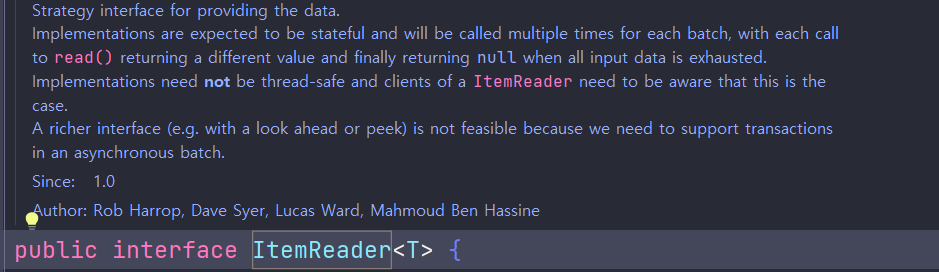
- ItemReader의 인터페이스를 살펴보면 ItemReader의 특징을 볼 수 있다.
1. Stateful 해야하고 여러번 호출 될 수 있어야한다.
2. .read 메서드는 각각 다른 값을 반환하며 마지막에는 null을 반환해야한다.
3. 구현체들은 보통 Thread-safe 할 필요없다.
=> .read 를 따라가보면 RepeatContext를 불러오는데 이는 ThrealLocal에서 가져온다.


c. 종류
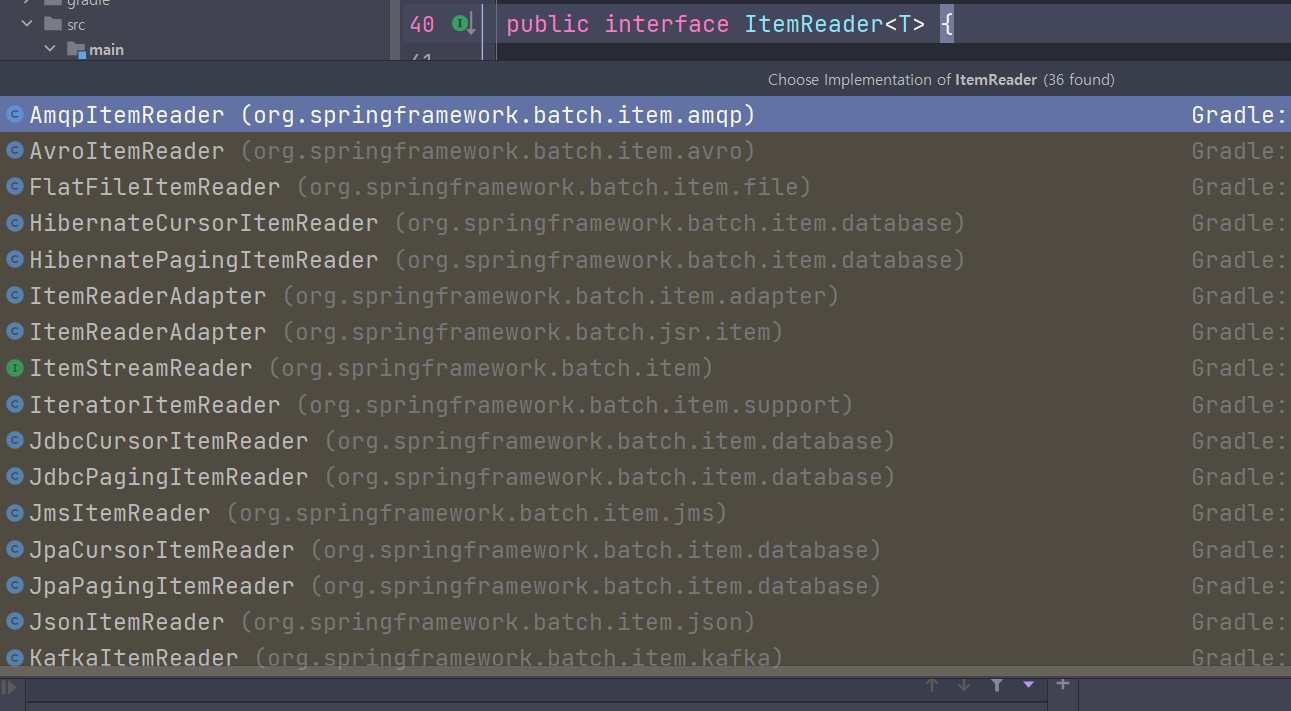
- ItemReader의 구현체로 꽤 다양한 입력 유형을 지원하는 것을 볼 수 있다. (아래 더 있음)
=> 바로 ItemReader를 상속받아서 구현하는 것보다 구현되어있는지 확인해보면 좋을것 같다.
d. with JPA
- 다른건 책에 있으니 DB의 데이터를 JPA로 읽어보는 예제를 만들어보자
- JPA 관련 ItemReader는 Cursor와 Paging을 지원하고 있다.
- JpaPagingItemReader로 DB의 데이터 값을 불러올 수 있도록 Bean을 설정해보았다
- 아래에 .setTransacted 설정을 볼수있는데 이는 영속성 컨텍스트에 데이터를 유지할지말지 설정할수있다.

@Bean
public JpaPagingItemReader<Input> jpaPagingItemReader(){
JpaPagingItemReader<Input> jpaPagingItemReader = new JpaPagingItemReader<>();
jpaPagingItemReader.setEntityManagerFactory(entityManagerFactory);
JpaNamedQueryProvider<Input> queryProvider = new JpaNamedQueryProvider<>();
queryProvider.setNamedQuery("input");
jpaPagingItemReader.setQueryProvider(queryProvider);
jpaPagingItemReader.setPageSize(3);
/* JpaNativeQueryProvider<Input> queryProvider = new JpaNativeQueryProvider<>();
queryProvider.setSqlQuery("SELECT * FROM INPUT");
queryProvider.setEntityManager(entityManager);
queryProvider.setEntityClass(Input.class);
jpaPagingItemReader.setTransacted(false);
*/
return jpaPagingItemReader;
}
@Entity
@NamedQuery(name = "input",query = "SELECT i FROM Input i")
@ToString
public class Input {
@Id
@GeneratedValue
Long id;
String value;
}- JpaPagingItemReader는 NativeQuery와 NamedQuery를 지원한다.
- 그리고 PageSize 설정도 따로 할수 있도록 되어있다. (default 10)
- Input 테이블에 레코드 10개, ChunkSize는 3, PageSize는 5로 해서 실행해보았다.


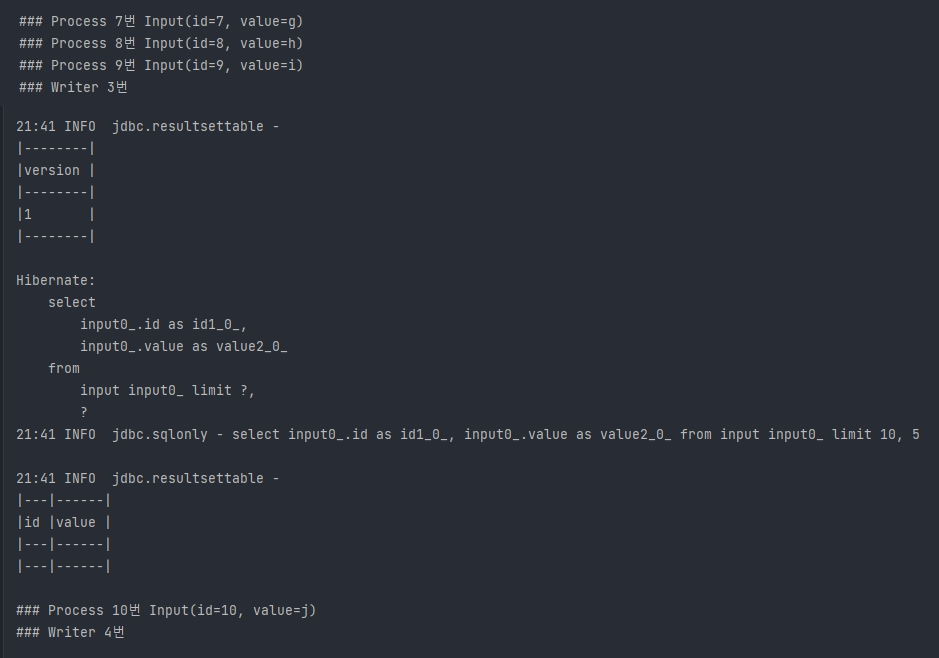
- ChunkSize와 Page 사이즈가 다르기 때문에 재미있는 결과가 나왔다.
- 순서
1. Reader는 첫번째 쿼리에서 5개의 데이터(PageSize)를 가져온다.
2. 이미 ChunkSize 만큼의 데이터를 충족했기 때문에 바로 Processor 넘어간다.
3. 다시 Reader로 돌아왔을때 2개의 데이터만 있기때문에 두번째 쿼리를 실행한다.
4. 총 7개의 데이터를 가지고 있기 때문에 Reader는 스킵되고 Processor <-> Writer로 바로 넘어간다.
5. 1개의 데이터만 있기때문에 Reader는 세번째 쿼리를 실행한다. (데이터는 없음)
6. Process-Writer는 마지막 데이터를 처리하고 배치는는종료된다.
- 여기서 알수있듯이 commit interval(ChunkSize)은 size만큼의 데이터를 충족하면 실행하지 않는다.
=> 즉 ChunkSize는 일반적으로 최대 실행 횟수로 볼 수 있을 것 같다. (ex. 한번에 3개, 3번에 3개)
e. ItemReaderAdapter
- 구현체 중에는 다른것과 다르게 ItemReaderAdapter 가 있다.
- 이 클래스는 Delegator를 상속받는데 즉 ItemReader를 기존 서비스 클래스를 사용할 수 있도록 해준다
- 간단하게 아래처럼 타겟 오브젝트와 메서드를 설정해주면 된다.
=> Delegator가 리플렉션을 이용해 타겟 메서드를 실행해준다.
@Bean
public ItemReaderAdapter<Input> itemReaderAdapter(){
ItemReaderAdapter<Input> adapter = new ItemReaderAdapter<>();
adapter.setTargetObject(legacyReaderService);
dapter.setTargetMethod("getInput");
return adapter;
}
'공부 > Spring Batch' 카테고리의 다른 글
| <Spring Batch> 6. Exception에 대한 skip 처리하기 (0) | 2022.01.12 |
|---|---|
| <Spring Batch> 5. ItemProcessor, ItemWriter (0) | 2021.10.03 |
| <Spring Batch> 3. 배치 테이블 Embedded DB(H2)로 따로 관리하기 (1) | 2021.09.27 |
| <Spring Batch> 2. JobRepository, Config Customizing (0) | 2021.09.22 |
| <Spring Batch> 1. JobParameters, ExecutionContext (0) | 2021.09.21 |
블로그의 정보
78개월 BackEnd
BFine