<Productivity> 두개의 엑셀파일 같은지 비교하기(feat. Chatgpt)
by BFine가. 배경
a. 기존 로직을 개선했는데..
- 가끔 배치 로직을 개선해야하는 경우가 생긴다. 데이터를 생성하는 배치의 경우에는 이전 로직과의 결과물이 같은지 비교해야하는 경우가 많다.
- 10개만 넘어가도 눈으로 찾기에는 쉽지도 않은데 몇백만건에 컬럼이 수십개 된다면은 AI가 아닌 이상 틀린그림찾기는 불가능하다.
- 업무 중 하나로 요런 부분이 많아서 하나 최대한 손이 덜가게 만들어서 써야겠다라는 생각이 들었다!
b. 개선 전후 로직에 대한 결과물 비교를 어떻게 할 수 있을까?
- 다양한 방법이 있겠지만 가장 좋은 것은 DB에서 SQL로 비교하면 좋겠지만 보통은 이전 버전 데이터는 삭제하고 만드니 현실적으로 쉽지않다.
=> 임시테이블을 만드는것도 방법이겠지만 비교 테이블이 여러개면 손이 많이가니까 단순하게 하고 싶어졌다.
- 요즘 DB 접속툴이 잘되어있어 excel, csv 추출이 간편하니 이전 데이터를 추출하고 개선 후 데이터를 추출해서 비교하는게 좋을 것 같다는 생각이 들었다.
c. 돈이 많다면..
- 여유가 있다면 diffchecker 쓰는게 정신건강에도 좋고 UI/UX도 잘되있어서 좋다!! (역시 돈이 최고다) https://www.diffchecker.com/
Diffchecker - Compare text online to find the difference between two text files
Compare text Diffchecker will compare text to find the difference between two text files.Just paste your files and click Find Difference
www.diffchecker.com
나. 엑셀 비교하는 코드 만들기 (with Python)
a. chatgpt의 10초 코딩
- 만들어달라고 하면 크게 두가지 라이브러리로 코드를 만들어준다. 몇번 테스트 해보니 크게 pandas와 openpyxl 두가지로 만들어준다.
- 원했던것이면서 잘돌아가는 수준까지 만들어주진 않았지만 살짝만 손보면 누구나 쉽게 만들 수 있을 것 같다. (일자리 뺏길 것 같다.)
b. openpyxl
- 엑셀 라이브러리로 다양한 기능을 할수 있다 예를들어 다른 데이터항목에만 색깔로 칠해준다던지 다양한 기능을 할 수 있다.
- 처음에 이걸로 알려줘서 괜찮다 싶었는데 데이터량이 조금 많아지니 동작을 안하고 오류가 발생해서 요걸로 대량 비교는 어려울듯 싶었다
c. pandas
- 데이터 분석 라이브러리로 python 쪽에서 상당히 잘알려진 라이브러리로 보인다. 데이터 분석용이지만 대량의 데이터를 빠르게 처리할 수 있다.
d. 코드
import pandas as pd
import sys
import os
import subprocess
def main(argv):
file_path1 = argv[1]
file_path2 = argv[2]
file1 = read_file(file_path1)
print('첫번째 파일읽기 완료')
file2 = read_file(file_path2)
print('두번째 파일읽기 완료')
print('파일 merge 시작')
merged_df = pd.merge(file1, file2, how='outer', indicator=True)
diff_df = merged_df[merged_df['_merge'] != 'both']
print('파일 merge 완료')
diff_filename = 'diff_' + extract_filename(file_path1) + '_' + file_path2
diff_df.to_excel(diff_filename,index=False)
print('쓰기완료')
output_file = os.path.abspath(diff_filename)
if os.path.exists(output_file):
if sys.platform == 'darwin':
subprocess.call(('open', output_file))
elif sys.platform == 'win32':
os.startfile(output_file)
else:
subprocess.call(('xdg-open', output_file))
def extract_extension(file_path):
_, file_extension = os.path.splitext(file_path)
return file_extension
def extract_filename(file_path):
file_name = os.path.basename(file_path)
filename_without_extension, _ = os.path.splitext(file_name)
return filename_without_extension
def read_file(file_path):
extension = extract_extension(file_path)
if ".xlsx" == extension:
return pd.read_excel(file_path)
if ".csv" == extension:
return pd.read_csv(file_path)
if __name__ == '__main__':
main(sys.argv)- chatgpt가 없었으면 시도도 못했을텐데 거의 90% 만들어준거에 10% 수정을 첨가 했다. ㅎㅎ
- 엑셀파일로 추출하면 최대 rows수(1,048,576)가 넘어가면 새로운 시트로 넘어가기 때문에 정확한 비교가 어려워서 고민하다가 제한없는 csv파일로도
비교할수 있도록 만들었다
다. 실행결과
a. 비교하기
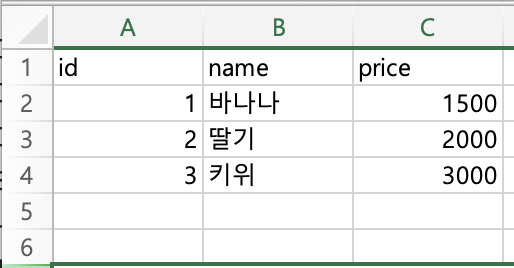
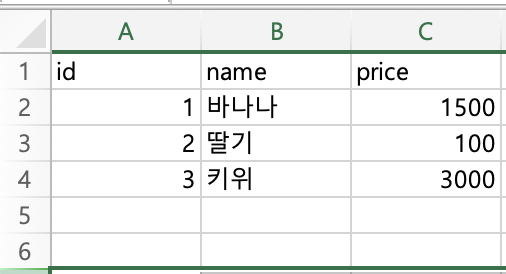
- 두개의 서로 다른 파일로 엑셀을 만들고 데이터를 약간만 바꿔서 실행해보면


- 각각에 파일에서 다른 데이터를 별도의 row로 보여주어서 어떤 항목이 각파일에 없는 항목인지를 볼 수 있다.!!
b. 한계
- 완전 동일한 row가 여러개일경우 비교할때 뻥튀기 되면서 stackoverflow가 발생할수 있다. 그렇기 때문에 데이터가 많은 경우
반드시 식별자를 넣어주는 것이 필요하다.
- 위에랑 동일하게 다른 데이터가 엑셀 최대 rows수(1,048,576)를 넘어가면 오류가 발생한다.
=> 결과 파일만들때 csv로 바꾸면 되긴하는데 csv는 가독성이 좋지 않아서 제외했다.
- 컬럼 수가 많아지는 경우 어느 데이터가 틀렸는지는 표시해주지는 않기 때문에 눈이 아플수 있다 ㅎㅎ
'공부 > Productivity' 카테고리의 다른 글
| <Productivity> Mac 메뉴바앱 일단 만들기 - 코드변환기 (4) | 2023.06.03 |
|---|
블로그의 정보
78개월 BackEnd
BFine