<GraphQL> 4. 동물원 예제 만들기 with Spring Boot
by BFine
가. 개요
a. 활용을 잘 할 수 있을까?
- 보통 어떻게 쓰는지 궁금해서 깃허브 찾아보니 Spring Boot grahpql 관련 레포지토리들이 대부분 기본 예제 뿐이고 스타일도 다른것 같다.
- 어떻게 하면 graphql의 목적에 맞게 쓸 수 있을지 하나하나 해보면서 예제를 만들어봐야겠다.
b. 무엇을 만들어 볼까
- 예제는 동물원에 동물을 등록하고 사육사와 매칭시키는 약간 백오피스(?) 스러운 느낌으로 만들려고 한다.
나. Animal
a. 동물 등록하기
- 먼저 스키마를 작성해보자. 등록부분은 Mutation에 요청을 담는 객체는 Input으로 만들었다.


- 그리고 대응하는 메서드를 만들자
@Component
@RequiredArgsConstructor
public class AnimalMutationResolver implements GraphQLMutationResolver {
private final AnimalRepository animalRepository;
private final ModelMapper modelMapper;
public AnimalDTO registerAnimal(InputAnimal inputAnimal){
Animal animal = Animal.builder()
.name(inputAnimal.getName())
.age(inputAnimal.getAge())
.kind(inputAnimal.getKind())
.animalType(inputAnimal.getAnimalType())
.build();
Animal save = animalRepository.save(animal);
return modelMapper.map(save,AnimalDTO.class);
}
}- 그리고 요청 테스트를 해보자

- 정상적으로 들어왔는지 확인만하면 되니까 Animal의 id값만 가져오도록 했다.
=> 확실히 Overfetching 도 없지만 내가 사용하는 값만 가져오는게 실무에서 트러블 슈팅할때 꽤 좋을것 같은 느낌이든다.
b. JPA Entity를 DTO로 써도 될까?
- registerAnimal 의 return 값은 Animal 으로 했다. 이부분은 고민을 해봤는데 DTO를 쓰는 이유가 레이어 분리 목적이 있지만 내가 원치않는 필드 값이 Client로 전달 되는것을 막기 위해서라고 개인적으로 보고 있는데 graphql은 이를 스키마에서 관리할 수 있으니 굳이 번거롭게 쓸 필요가 없을것 같다.
- 해보니까 응답 필드가 추가되는 경우가 발생하는데 JPA Entity와는 관련이 없는 부분도 있어 좋은 형태는 아닌것 같아서 DTO로 다시 변경했다..
c. 조회하기

- 보면 메서드 이름을 명사로 만들어보았다. 개인적인 생각으로 REST API 호출했는데 메서드 이름처럼 나오는 경우는 본 적이 없기 때문에 일반적인 메서드
이름보다는 명사로하는게 직관적이고 조합하기도 편하지 않을까? 라는 생각이 든다
@Component
@RequiredArgsConstructor
public class AnimalQueryResolver implements GraphQLQueryResolver {
private final AnimalRepository animalRepository;
private final ModelMapper modelMapper;
public List<AnimalDTO> animals(){
List<Animal> animalList = animalRepository.findAll();
return animalList.stream()
.map(animal -> modelMapper.map(animal, AnimalDTO.class))
.collect(Collectors.toList());
}
public AnimalDTO animal(Long id){
Animal animal = animalRepository.findById(id).orElseThrow();
return modelMapper.map(animal, AnimalDTO.class);
}
}

다. Employee
a. 동물원에 직원들!
- 이제 동물을 등록했으니 직원들도 거의 비슷한 형태로 동일한 Entry Point를 작성했다.
- 그리고 가장 중요한 부분은 직원들 중에는 사육사가 있고 각각 담당하는 동물들이 있을 것 이다. 이부분을 만들어보자.
b. 동물에 사육사 배정하기
- 동물들은 담당 사육사들이 있고 사육사들은 여러 동물들을 담당하는 다대다 관계인 형태이다.
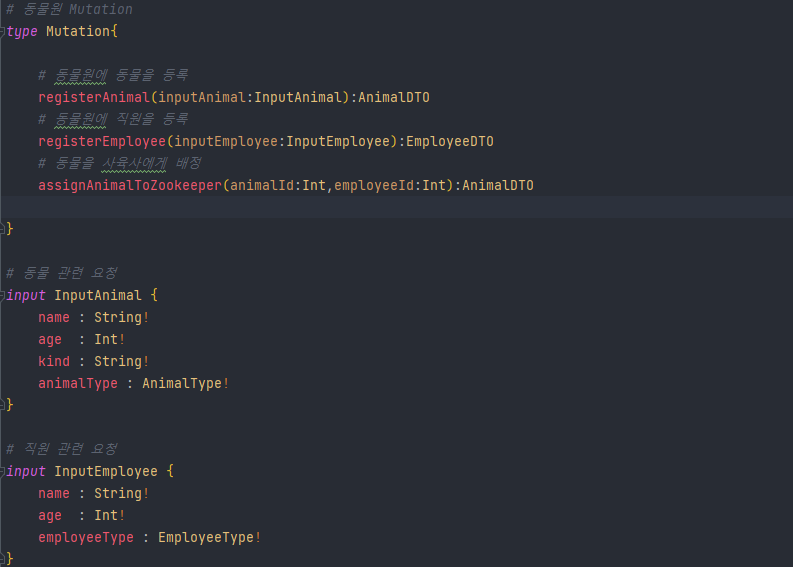
- 간단하게 동물과 직원의 아이디를 가지고 매핑 테이블에 추가하도록 만들어 보았다.
@Transactional
public DataFetcherResult<AnimalDTO> assignAnimalToZookeeper(Long animalId, Long employeeId){
Animal animal = animalRepository.findById(animalId).orElseThrow();
Employee employee = employeeRepository.getById(employeeId);
EmployeeAnimalPK pk = EmployeeAnimalPK.builder().animal(animalId).employee(employeeId).build();
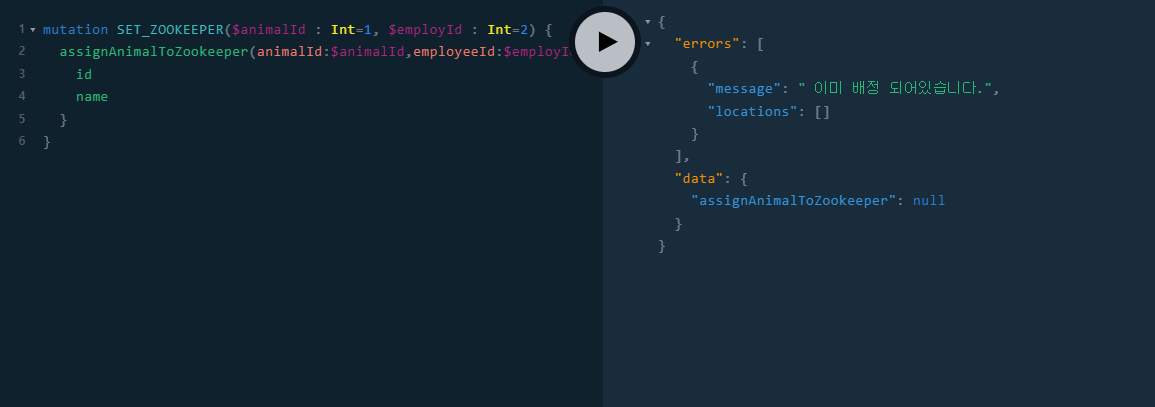
if(employeeAnimalRepository.existsById(pk)){
return DataFetcherResult.<AnimalDTO>newResult()
.error(new GenericGraphQLError(" 이미 배정 되어있습니다."))
.build();
}
EmployeeAnimal employeeAnimal = EmployeeAnimal.builder()
.animal(animal)
.employee(employee)
.build();
employeeAnimalRepository.save(employeeAnimal);
return DataFetcherResult.<AnimalDTO>newResult()
.data(modelMapper.map(animal,AnimalDTO.class))
.build();
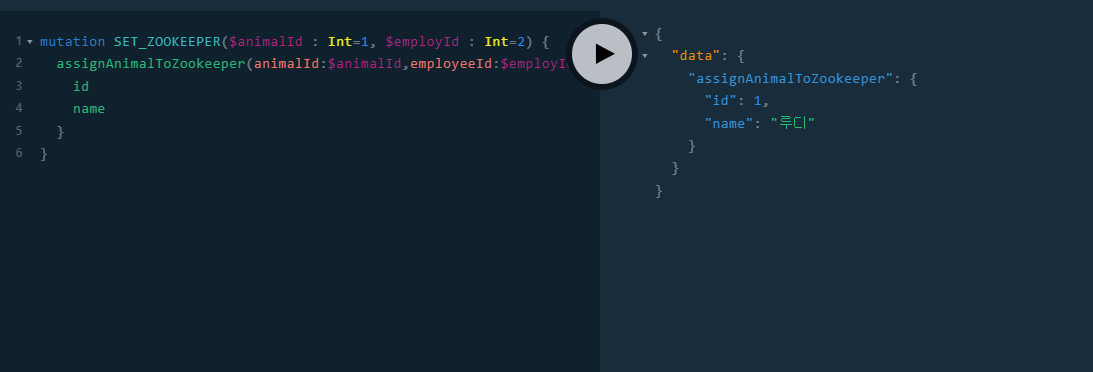
}- 여기서 보면 DataFecherResult가 있는데 여기에는 GraphQLError를 컨트롤 할 수가 있어 이를 이용하여 중복에 대한 예외처리를 해보았다.
- 테스트 해보면 정상적으로 처리가 되는 것을 볼 수 있다.
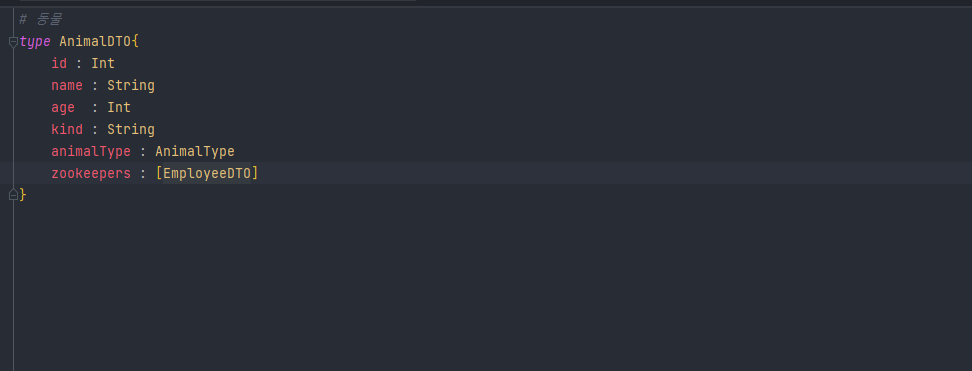
c. 동물 조회 시 사육사들도 추가하기
- 동물 조회 시 배정된 사육사들도 나오면 좋을 것 같으니 한번 추가를 해보자
@RequiredArgsConstructor
@Component
public class ZookeeperResolver implements GraphQLResolver<AnimalDTO> {
private final AnimalRepository animalRepository;
private final ModelMapper modelMapper;
@Transactional
public List<EmployeeDTO> zookeepers(AnimalDTO animalDTO){
Animal animal = animalRepository.findById(animalDTO.getId()).orElseThrow();
List<EmployeeAnimal> employeeAnimalList = animal.getEmployeeAnimalList();
List<Employee> employeeList = employeeAnimalList.stream()
.map(EmployeeAnimal::getEmployee)
.collect(Collectors.toList());
return employeeList
.stream()
.map(employee -> modelMapper.map(employee, EmployeeDTO.class))
.collect(Collectors.toList());
}
}
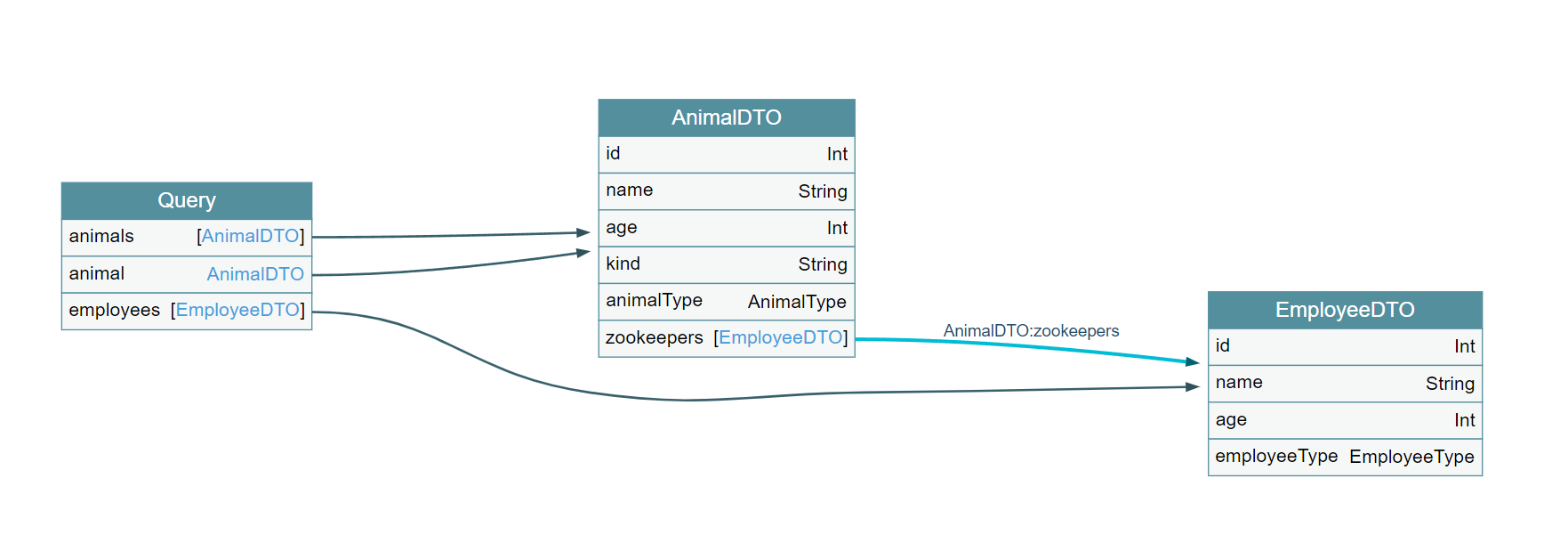
- 이 zookeepers 부분은 animal 메서드가 아닌 따로 클래스를 만들어서 GraphQLResolver를 이용해서 만들었다.
- 위의 query와는 다르게 entry point는 아니어서 따로 요청할 수 있는 부분은 아니지만 개별적인 메서드 실행을 갖는다고 보면된다.
=> 로직을 보면 응답값이 AnimalDTO가 아니다. 즉 이부분은 return값에 대한 조립을 graphql이 직접한다는 것을 알수 있다.
- 테스트를 해보면 정상적으로 동물에게 배정된 사육사들을 가져올 수가 있다.
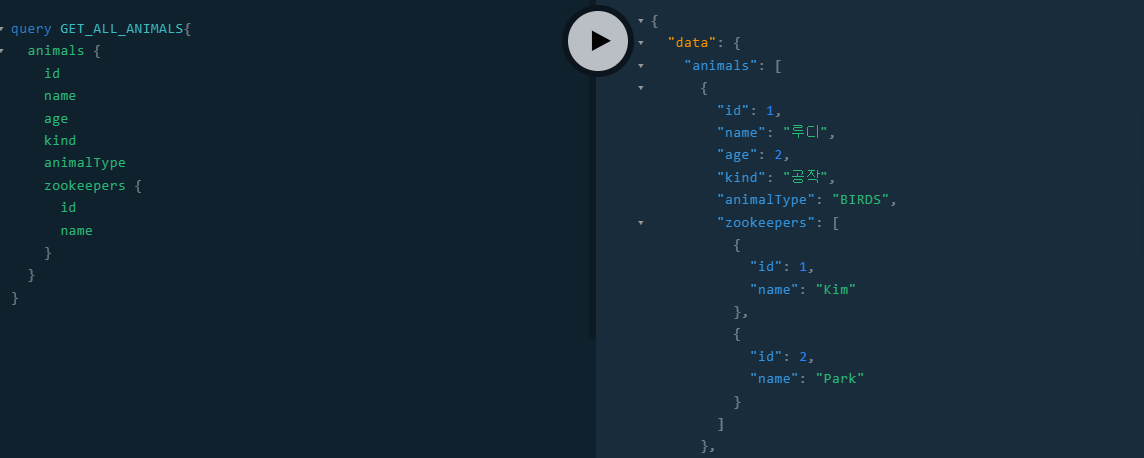
- 여기서 재미있는 부분은 아래처럼 zookeepers를 응답으로 지정하지 않은 경우에는 위의 zookeepers 메서드는 실행되지 않는다.
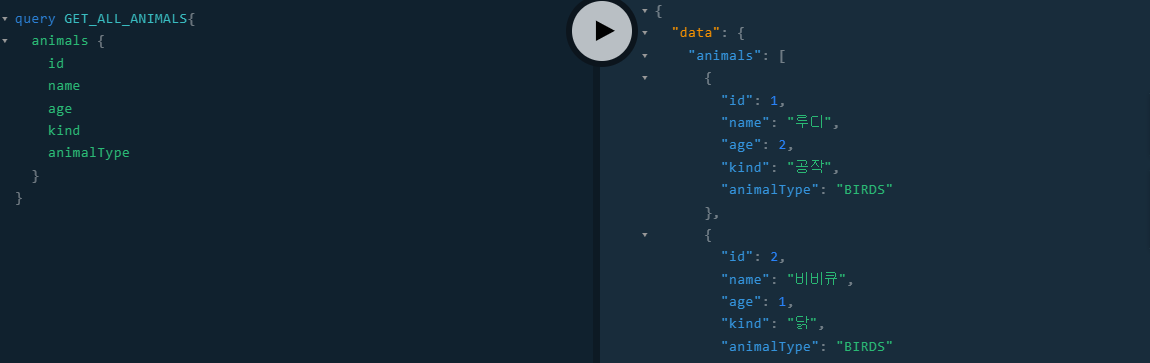
- 내가 원하는 데이터가 아니면 실행하지 않는다 라는 점에서 Overfetching에 부하까지 줄일수 있는 장점인것으로 느껴진다.
=> zookeepers 가 느리다면 REST API라면 필요없는 곳에서는 분기로직을 추가한던지 아니면 API를 새로 만들고 DTO를 추가하는등이 필요했을 것이다.
- 물론 보통 DB sql을 보면 한번에 많은 데이터를 가져온다. 분리처리를 했을 경우 쿼리가 추가적으로 발생할 수 있다는 부분에서
어떻게 해야 더 나을지는 고민이 필요할 것 같기도 한다.
'공부 > GraphQL' 카테고리의 다른 글
| <GraphQL> 6. DataLoader with Spring Boot (0) | 2022.04.30 |
|---|---|
| <GraphQL> 5. 비동기 처리 / N+1 문제 with Spring Boot (0) | 2022.04.06 |
| <GraphQL> 3. Exception Handling with Spring Boot (0) | 2022.03.27 |
| <GraphQL> 2. Query와 Type with Spring Boot (2) | 2022.03.26 |
| <GraphQL> 1. 설정하기 with Spring Boot (2) | 2022.03.14 |
블로그의 정보
57개월 BackEnd
BFine