<GraphQL> 5. 비동기 처리 / N+1 문제 with Spring Boot
by BFine
가. 분리한 Resovler가 오래걸린다면?
a. Tracing
- 지난 포스팅에서 .animals 을 불러올때 .zookeeper를 추가했고 GraphQLResolver로 분리를 해보았다. 만약 이부분이 오래걸리면 어떻게 될까 알아보자
@Transactional
public List<EmployeeDTO> zookeepers(AnimalDTO animalDTO) throws InterruptedException {
TimeUnit.MILLISECONDS.sleep(200);
Animal animal = animalRepository.findById(animalDTO.getId()).orElseThrow();
List<EmployeeAnimal> employeeAnimalList = animal.getEmployeeAnimalList();
List<Employee> employeeList = employeeAnimalList.stream()
.map(EmployeeAnimal::getEmployee)
.collect(Collectors.toList());
return employeeList
.stream()
.map(employee -> modelMapper.map(employee, EmployeeDTO.class))
.collect(Collectors.toList());
}- 200ms sleep을 주고 전체 animals를 불러오는 테스트를 해보자

- 따로 처리하지 않는다면 동기처리하며 예상한대로 전파되는 느낌으로 응답이 늦어지는 것을 볼 수가 있다.
b. 비동기 처리하기
- 간단하게 다른 곳에서 CompletableFuture 쓰는 것과 동일하게 사용하면 된다.
@Slf4j
@RequiredArgsConstructor
@Component
public class ZookeeperResolver implements GraphQLResolver<AnimalDTO> {
private final ZookeeperService zookeeperService;
public CompletableFuture<List<EmployeeDTO>> zookeepers(AnimalDTO animalDTO){
return CompletableFuture.supplyAsync(()-> zookeeperService.getEmployeeDTO(animalDTO));
}
}@Component
@RequiredArgsConstructor
public class ZookeeperService {
private final AnimalRepository animalRepository;
private final ModelMapper modelMapper;
@Transactional
public List<EmployeeDTO> getEmployeeDTO(AnimalDTO animalDTO){
try {
TimeUnit.MILLISECONDS.sleep(200);
} catch (InterruptedException e) {
e.printStackTrace();
}
Animal animal = animalRepository.findById(animalDTO.getId()).orElseThrow();
List<EmployeeAnimal> employeeAnimalList = animal.getEmployeeAnimalList();
List<Employee> employeeList = employeeAnimalList.stream()
.map(EmployeeAnimal::getEmployee)
.collect(Collectors.toList());
return employeeList
.stream()
.map(employee -> modelMapper.map(employee, EmployeeDTO.class))
.collect(Collectors.toList());
}
}
- 기존 로직에서 Service 클래스로 분리해서 비동기 처리를 해보았다.
=> 분리한 이유는 graphql이랑은 관련이 없는 부분인데 내부에서 비동기 로직을 추가하는 경우 개별적인 @Transactional 을
인식하지 못하기 때문에 could not initialize proxy - no Session 를 보게 된다..
- 테스트 해보면 비동기 처리되어 응답시간이 단축되는 것을 볼 수 있다.

나. N+1 문제
a. 동물들의 어디에 있지?
- 동물원에 종별로 동일한 곳에 위치하고 있다. 시스템상에 동물 친구들이 어디에 위치하고 있는지도 알면 좋을 것 같다.
- 관련 테이블을 생성하고 종류에 따른 위치를 insert 했다

b. 로직 만들기
- .zookeepers를 만들때와 동일하게 GraphQLResolver를 사용해서 별도의 메서드로 만들어보자.

@RequiredArgsConstructor
@Component
public class PlaceResolver implements GraphQLResolver<AnimalDTO> {
private final PlaceRepository placeRepository;
public String location(AnimalDTO animalDTO){
Place place = placeRepository.findByKind(animalDTO.getKind());
return place.getPlaceName();
}
}
- 간단하게 만들었고 테스트 해보면 아래와 같이 나온다.
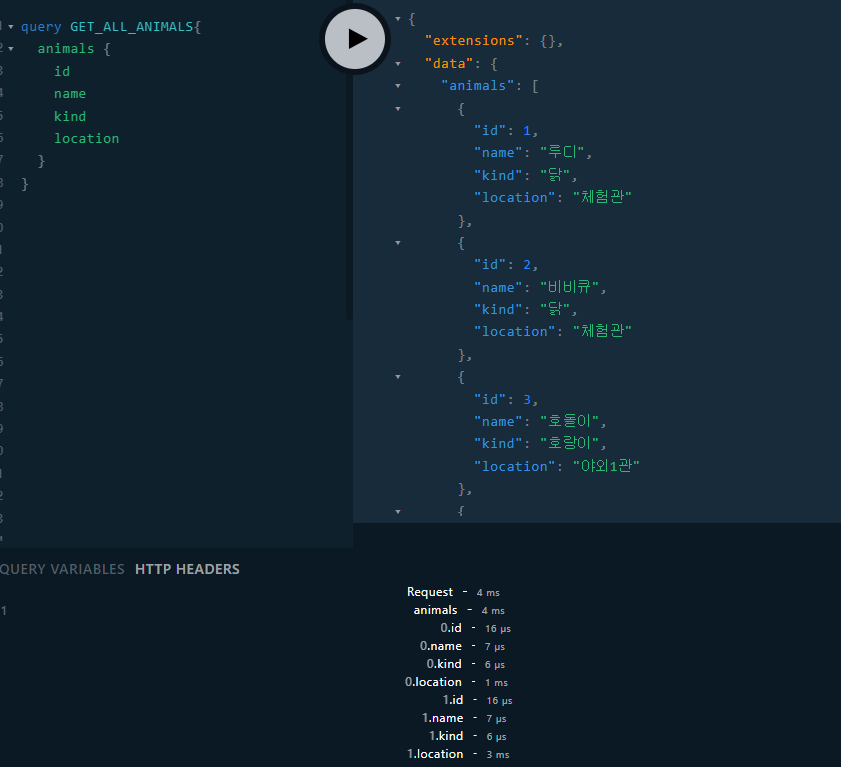
c. 비효율적인 N+1 문제
- JPA에서 단골로 나오는 N+1 문제가 여기서도 볼 수 있는데 보면 동물들의 수 만큼 .location 메서드가 실행되어 DB를 호출하고 있다.
- 각각 동물들과 달리 동물원의 위치와 종류는 한정적인데 여기서는 만마리의 동물이 있다면 만번의 쿼리가 발생하게 된다.
- 한번에 가져와서 Map에 담아서 value만 가져온다면 DB에 한번만 갔다와도 되는데 비효율적인 모습이다.
다. DataLoader
a. Service
- 위의 문제를 해결하기 위해 먼저 GraphqlResolver에 있던 로직을 분리해서 Service 클래스를 생성해보자
@RequiredArgsConstructor
@Service
public class PlaceService {
private final PlaceRepository placeRepository;
public List<String> getLocationList(List<String> kindList){
List<Place> placeList = placeRepository.findAll();
Map<String, String> placeMap = placeList.stream()
.collect(Collectors.toMap(Place::getKind, Place::getPlaceName));
List<String> locationList = kindList.stream()
.map(placeMap::get)
.collect(Collectors.toList());
return locationList;
}
}- 아까와는 다르게 전체의 kind 를 List형태로 받아서 DB에 있는 place 정보를 한번에 가져와서 대응하는 location을 가져오는 것을 볼 수 있다.
b. DataLoader
- 위의 로직을 실행시키기 위해서는 Key값에 대한 수집(여기서는 kind)과 해당 로직을 수행하여 값들 (여기서는 location) 가져오는 역할이 필요하다.
- 이 역할하는게 DataLoader 이고 죽 Key값들에 대해 Batch Loading을 지원하는 인터페이스이다.
c. GraphQLServletContextBuilder
- 위의 DataLoader는 DataLoaderRegistry에 등록해서 사용하며 이를 위해서는 GraphQLServletContextBuilder 설정이 필요하다.
@RequiredArgsConstructor
@Component
public class ConfigGraphqlContextBuilder implements GraphQLServletContextBuilder {
private final PlaceService placeService;
@Override
public GraphQLContext build(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse) {
return DefaultGraphQLServletContext.createServletContext()
.with(dataLoaderRegistry())
.with(httpServletRequest)
.with(httpServletResponse)
.build();
}
@Override
public GraphQLContext build(Session session, HandshakeRequest handshakeRequest) {
return DefaultGraphQLWebSocketContext.createWebSocketContext()
.with(session)
.with(handshakeRequest)
.build();
}
@Override
public GraphQLContext build() {
return new DefaultGraphQLContext();
}
private DataLoaderRegistry dataLoaderRegistry(){
DataLoader<String, String> locationDataLoader = DataLoaderFactory
.newDataLoader(kindList -> CompletableFuture.supplyAsync(() -> placeService.getLocationList(kindList)));
return DataLoaderRegistry.newRegistry()
.register("locationDataLoader",locationDataLoader)
.build();
}
}
- 등록한 DataLoader는 GraphQLResolver에서 DataFetchingEnvironment 를 통해 사용할 수가 있다.
@RequiredArgsConstructor
@Component
public class PlaceResolver implements GraphQLResolver<AnimalDTO> {
public CompletableFuture<String> location(AnimalDTO animalDTO, DataFetchingEnvironment environment){
DataLoader<String, String> locationDataLoader = environment.getDataLoader("locationDataLoader");
return locationDataLoader.load(animalDTO.getKind());
}
}
- 이제 한번 실행을 해서 테스트 해보면
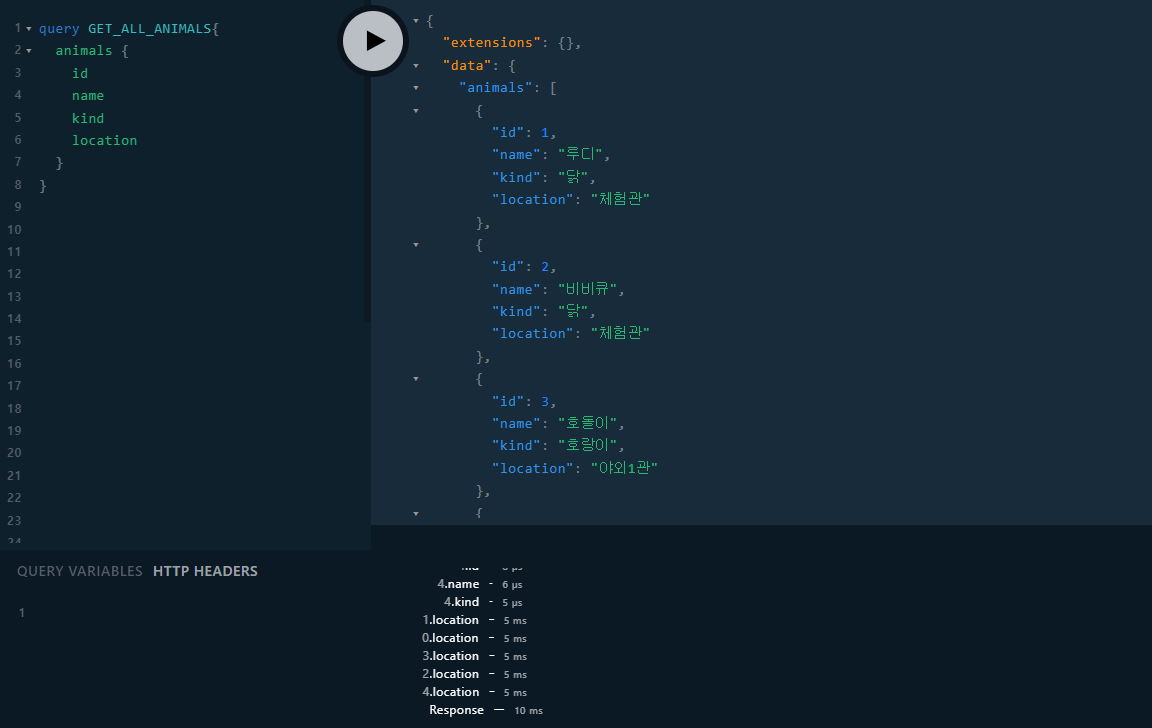
- 처음 했을때와 다르게 location이 연관된 값들과 별개로 따로 처리되는 것을 볼 수 있다.
- 로그를 추가해서 어떻게 실행이 이루어지는지 확인 해보면

- 먼저 Resovler가 동물의 수 만큼 실행된 이후에 Service 실행한 것을 볼 수 있으며 쿼리는 한번으로 줄일 수 있었다.
참고 : https://youtu.be/UOyIQCsVii4 , https://youtu.be/tbxskis_ny4
여담이지만 개인적으로 설정 Context에 Service 클래스가 들어가는게 맘에 들지는 않는다... 나중에 업무 서비스에 할 수 있다면 도입해봐야겠다.
'공부 > GraphQL' 카테고리의 다른 글
| <GraphQL> 6. DataLoader with Spring Boot (0) | 2022.04.30 |
|---|---|
| <GraphQL> 4. 동물원 예제 만들기 with Spring Boot (0) | 2022.04.02 |
| <GraphQL> 3. Exception Handling with Spring Boot (0) | 2022.03.27 |
| <GraphQL> 2. Query와 Type with Spring Boot (2) | 2022.03.26 |
| <GraphQL> 1. 설정하기 with Spring Boot (2) | 2022.03.14 |
블로그의 정보
57개월 BackEnd
BFine